


What is AWS AppSync
AWS AppSync is a managed API service that you can use in your serverless backends. In this chapter we’ll go over it in detail:
Let’s get started!
Background
If you’re already familiar with API Gateway, you may be wondering why you would need to learn yet another service. It all comes down to the protocol that you want to use: REST or GraphQL.
GraphQL
GraphQL was created by Facebook in 2012 to reduce the amount of network traffic required by their mobile app’s news feed. Facebook released GraphQL as an open-source project a few years later, and it has been slowly catching on. In 2016, GitHub converted their public API to GraphQL.
GraphQL, or graph query language, is an API protocol built on top of Representational State Transfer (REST). It enables you to specify what data will be in the response by filtering records or specifying which properties you need.
According to Smartbear’s State of the API report in 2020 only about 19% of responding organizations use GraphQL. The majority (at least 82%) of organizations use some form of REST.
GraphQL shines anytime you want to limit the number of requests sent to the server and the size of the responses coming back. It allows you to stitch together data from multiple sources on the backend. It can also handle nested data, so you don’t have to send a request to get a list of IDs then send another request to get data associated with each ID. Finally, GraphQL allows you to specify the properties that you want in your response. This helps you avoid overfetching, which is wasting bandwidth downloading something that you don’t actually want or need.
GraphQL on AWS Lambda
If you decide to use GraphQL in a serverless application, how do you run the server? In AWS the serverless compute service is AWS Lambda. While they do have some limitations, it’s not that difficult to run a GraphQL server on a Lambda.
There are two main GraphQL server libraries that can run in an AWS Lambda. Apollo Server provides a support package to get it running in a lambda. The other option is an Express middleware—Express GraphQL—that enables you to run GraphQL along with REST endpoints.
Apollo Server is the more popular of the two options and should be your go-to option most of the time. If you already have a REST API running on a Lambda, however, and want to convert it to GraphQL then the simplicity of adding a middleware plugin to your server is a huge win. Just add express-graphql to your project and you can slowly replace your REST paths with GraphQL queries and mutators.
Speaking of middleware plugins, that’s another reason to stick with Express: it has a lot of plugins. If Apollo Server doesn’t already support the authentication that you want to use, chances are that someone has written an express middleware for it.
What is AWS AppSync
Lambdas are great for a lot of things, but running a GraphQL server on one can get tricky. Especially when you want to start using features like subscriptions. AppSync is AWS’s solution to that problem.
AWS AppSync is a managed GraphQL API service that, in true serverless form, allows you to create an API without worrying about how to host it. It provides full support for subscriptions and a couple of features to simplify getting data from other AWS services.
AppSync APIs have three components that you need to define: a schema, resolvers, and data sources. Combining these three items allows your API to interact with resources and translate responses into the desired format.
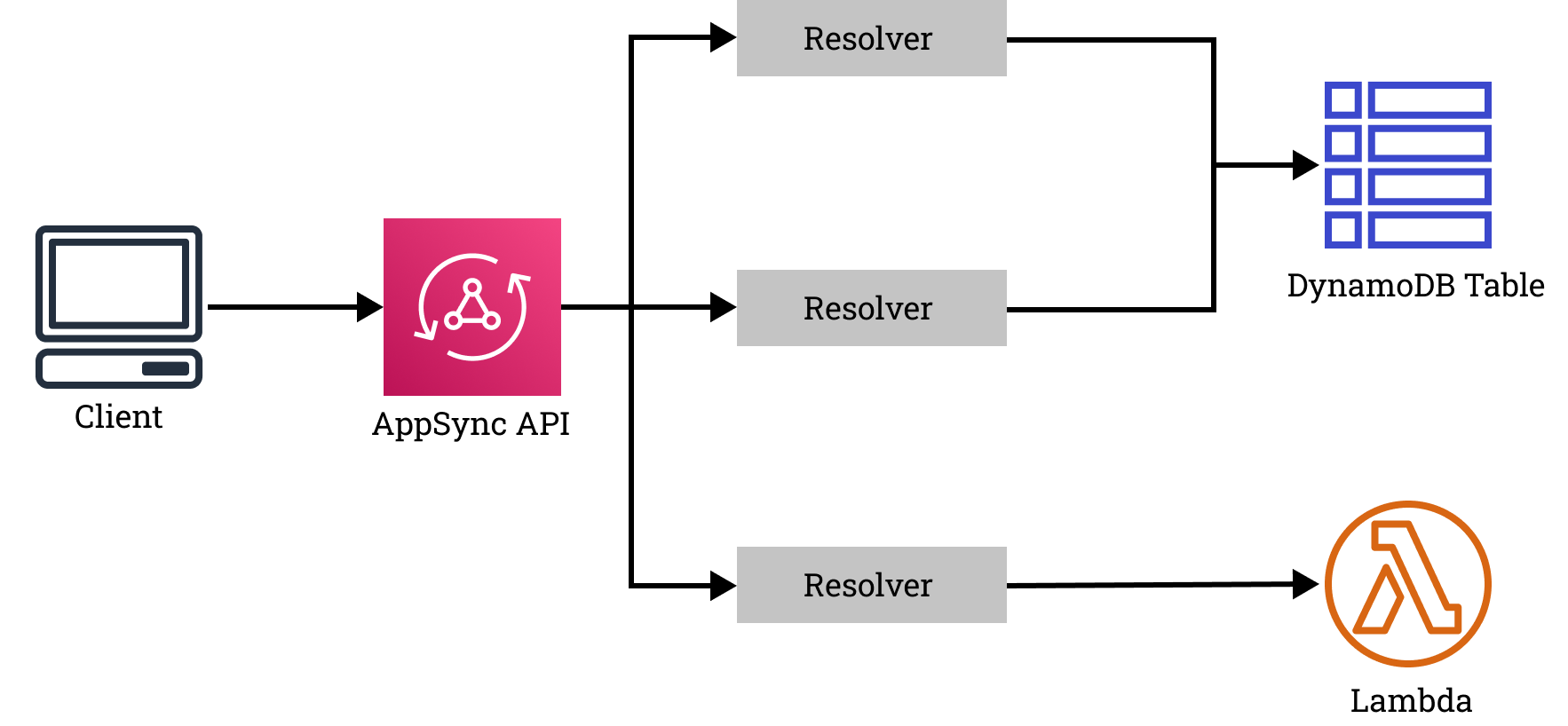
When a request first comes in, AppSync verifies it using the schema. The authorization of the request is verified against some optional type decorators and the requested properties are checked to make sure they’re valid.
Once AppSync has determined what object type is being requested, and that the user is allowed to request it, it finds the resolver associated with that type. The resolver defines request and response templates that use simple logic to translate the data between GraphQL and a data source.
After the GraphQL query has been translated by a resolver, it’s sent to a data source. The data source defines a database connection, lambda ARN, or some other destination that the request is sent to. Once the resource runs whatever action was requested, it returns the result to a response template which translates it back into a format compliant with your schema.
There are currently six types of data sources supported by AppSync:
- DynamoDB
- ElasticSearch
- Lambda
- None
- Http
- RDS
If you need to use data from an AWS service that isn’t in the list, you can use a Http data source.
The biggest drawback to AppSync is the development experience. Resolver template development is notoriously difficult due to its use of Apache VTL.
AppSync Pricing
There are a few different things that you get charged for when using AppSync:
- queries/mutations
- subscription updates
- minutes that a client is listening to a subscription
- data transferred out
- optionally caching
The following table details the current prices charged for running an AppSync API. For the most up to date pricing, see the AWS AppSync pricing page.
| Description | Price |
|---|---|
| 1 Million Queries/Mutations | $4.00 |
| 1 Million 5 kb Updates | $2.00 |
| 1 Million Minutes Connected to Subscription | $0.08 |
| 1 Gb Transferred to the Internet | $0.09 |
You can optionally enable caching for your AppSync API. You select an instance type from a handful of options. Each instance type has an hourly rate associated with it that currently ranges from $0.044 to $6.775. See the AWS AppSync pricing page for the most up to date prices.
AppSync Concepts
Now let’s dive into the major concepts behind AppSync. Starting with data sources.
Data Sources
Data sources in AWS AppSync are services, databases, or APIs that hold the data your GraphQL API queries and uses to populate your schema.
There are just a handful of data sources that AWS AppSync supports, such as Amazon DynamoDB, AWS Lambda (Lambda can allow you to use other options, such as RDS or ElastiCache), and Amazon Elasticsearch Service.
SST’s AppSyncApi construct makes creating data sources a lot easier. We’ll be looking at some examples of how to do this below.
You’ll need data sources whenever you need to fetch and manipulate data. However, in some cases where you might only want to perform data transformation with resolvers and subscriptions to be invoked by a mutation, you might not need a data source.
Using the SST AppSyncApi, you could add a data source to your GraphQL API easily without having to log in to your AWS console.
import { AppSyncApi } from "@serverless-stack/resources";
new AppSyncApi(this, "GraphqlApi", {
graphqlApi: {
//...
},
dataSources: {
notesDS: "functions/notes.main",
},
resolvers: {
//...
},
}
Resolvers
Resolvers in GraphQL are functions that return responses when you query a GraphQL API. It’s a function mapped to a field in your GraphQL schema and is responsible for returning results for that field.
The function generally contains four arguments:
parentargumentscontextinfo
Here is what the function definition looks like:
fieldName: (parent, args, context, info) => data;
Now let’s take a look at what they mean:
- parent: The parent, sometimes referred to as the
root, is the object that holds the return value of the reference field. It’s always executed before the resolvers of the field’s children. It’s an optional parameter. - args: All the GraphQL arguments provided for a certain field are accessible in the args. For example, when executing
Query{ todo(id: "2") }, the args here is the object passed to the todo resolver{ "id": "2" }. - context: All resolvers that execute for a particular operation share the same context and can be accessed across all the resolvers with the same argument in the resolver.
- info: This argument contains information about the execution of the query such as the field’s name and the field’s path.
Assuming you have a schema:
type Todo {
id: ID!
description: String!
checked: Boolean!
}
type Query {
todos: [Todo]
todo(id: ID!): Todo
}
You’d might then have a resolver to query the todos schema type.
Query: {
todos: () => Todo.find(),
todo: (_, { id }) => Todo.findById(id),
},
Here we are using Mongoose to query our MongoDB database.
In the todos resolver function, we didn’t need to pass any arguments. However in the todo function, we need to pass a context; the todo id.
Now with the SST AppSyncApi construct, you can configure resolvers:
import { AppSyncApi } from "@serverless-stack/resources";
new AppSyncApi(this, "GraphqlApi", {
graphqlApi: {
schema: "graphql/schema.graphql",
},
dataSources: {
todoDS: "src/todos.main",
},
resolvers: {
"Query todos": "todoDS",
},
});
Mutations
A mutation is a resolver function that modifies the data store and returns a value. It can be used to insert, update, or delete data. The only difference between a query resolver function and a mutation is the use of mutation in the resolver map:
import Todo from "./Todo";
export default {
Query: {
todos: () => Todo.find(),
todo: (_, { id }) => Todo.findById(id),
},
Mutation: {
createTodo: (_, { description }) => {
const todo = Todo.create({ description, checked: false });
return todo;
},
checkedTodo: (_, { id, checked }) =>
Todo.findByIdAndUpdate(id, { checked: checked }),
updateTodo: (_, { id, description }) =>
Todo.findByIdAndUpdate(id, { description }),
deleteTodo: (_, { id }) => Todo.findByIdAndDelete(id),
},
};
You’ll use a mutation in your resolver if you need to modify data in your data store.
Like the queries, you can easily add mutations to your resolver in the SST AppSyncApi:
import { AppSyncApi } from "@serverless-stack/resources";
new AppSyncApi(this, "GraphqlApi", {
graphqlApi: {
schema: "graphql/schema.graphql",
},
dataSources: {
todoDS: "src/todos.main",
},
resolvers: {
"Query todos": "todoDS",
"Mutation createNote": "todoDS",
"Mutation updateNote": "todoDS",
"Mutation deleteNote": "todoDS",
},
});
Subscriptions
GraphQL subscriptions maintain an active connection with the server (usually through WebSockets), listens to real-time messages from the server, and allows bi-directional communication between the client and the server. In a nutshell, it listens to activities on the server and sends updates to the client in real time.
In most cases, you will have to pull data intermittently with queries on demand (like clicking a button or refreshing a page), but in some cases, you might need to use a subscription to notify the client of small, incremental changes to large objects. You might also need to use subscriptions in situations where there is low latency and a real-time update is required.
To create a subscription, you’ll first need to create a schema type of subscription and add the AWS AppSync annotation @aws_subscribe() to it.
type Subscription {
newTodo: Todo
@aws_subscribe(mutations: ["newTodo"])
}
Permissions
In most cases, you want your Lambda functions to be able to access only some or all of your AWS services such as S3.
For example, using SST AppSyncApi, you can allow all the Lambda functions in your API to access S3 (or any other resource).
import { AppSyncApi } from "@serverless-stack/resources";
new AppSyncApi(this, "GraphqlApi", {
graphqlApi: {
schema: "graphql/schema.graphql",
},
dataSources: {
todoDS: "src/todos.main",
},
resolvers: {
"Query todos": "todoDS",
"Mutation createNote": "todoDS",
"Mutation updateNote": "todoDS",
"Mutation deleteNote": "todoDS",
},
});
// Allow the AppSync API to access S3
api.attachPermissions(["s3"]);
Alternatively, you can add permission for a specific Lambda function. Such as the function for a particular data source to access AWS S3.
api.attachPermissionsToDataSource("todoDS", ["s3"]);
Here you are referring to the data source by the key, todoDS. This is to make sure that only those functions have the permission to your services.
Wrapping up
And that’s it. Now you’ve got a good sense of what is AWS AppSync and how to use it to build a GraphQL backend. To get started with your first AppSync application, check out our example — How to create a serverless GraphQL API with AWS AppSync.
For help and discussion
Comments on this chapter